
Using Machine Learning to Rapidly Discover & Scale Profitable Opportunities
The Business Challenge:
When a mid-sized email marketing client approached us, they were looking for a way to simplify and automate a complicated and entangled process of identifying good customers to send emails to. Their process began with a set of simple rules that prioritized past engagers by recency, by source, and by offer. Over the years, rules accrued and accrued, until the process to determine if an email should be sent became a convoluted set of conditional statements. The rules were interconnected, making it impossible to know the effect of one rule change. This cumbersome, inscrutable process, though it functioned, was making it impossible for them to move quickly on new opportunities. Additionally, the deeply interconnected rule set made it impossible to measure which pieces of the process were actually adding value, and which pieces were no longer contributing.
The Komodo Solution:
Komodo worked with the client to identify the most valuable objectives. They wanted a new process that would help them identify the most profitable email addresses so they could maximize the profitability of their campaigns. We then examined the data available. It turned out the client was sitting on a gold mine of user engagement data. Their current process, having initially been built years before, could only intake a few different data types and generate results for one email platform. They wanted some way to take in more data types and produce more generally useful results.
The goal was to build a more sophisticated model that could ingest the large amounts of existing data to produce a daily offer recommendation score and other important status details for each of this client’s 2MM active users. Then, any downstream platform can consume these outputs, laying the groundwork for data-driven decision making. Komodo got to work prototyping models, testing them and refining them. Within 3 months, Komodo prototyped a model that would intake and analyze significantly more data and whose outputs were consumable by the current platform.

Figure 1: Early versions of the model emphasized rapid iteration to assess quality of predictions. Infrastructure was simple and cheap. Once we identified the right model to build and the right magnitude of data to process, data engineering and devops were able to scale a model with confidence.
With a model that could confidently identify the best users that engaged at 1.5x the average rate, it was time to make some data-driven decisions. Komodo conducted a detailed analysis of the deployment strategy and subsequent impact and discovered something interesting: the most profitable email addresses the model was recommending were already being targeted heavily by the client. While the model could help the client prioritize which users to mail first and what to mail them, this level of user-targeting would require a dramatic shift in the client’s mailing strategy. This would delay ROI by requiring an infrastructure project first.
After this discovery, we began to change our focus. We continued working with them to pivot and find a strategy that would exploit their existing infrastructure and new model outcomes, but would provide more impact sooner.
After looking at the data again, we turned our model onto a different set of users–the cohort of emails that fell out of the clients’ current process of identifying active users. This cohort of inactive users made up 98% of their user database: a huge opportunity. This was a chance for Komodo’s data engineering and devops skills to shine – we refactored our data pipelines to be able to process information and generate scores for not just 2MM active users but also another 100MM of the inactive users for scores.
As part of this process, we had to significantly augment the amount of data available for these users. To do so, we evaluated over a dozen data vendors using a profitability framework that we built for our client. With a portfolio of vendors, we were able to negotiate competitive prices for our client.
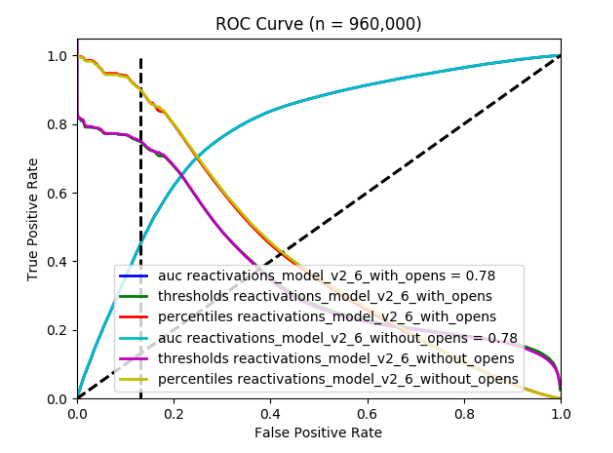
Figure 2: The model in its maturity had excellent predictive power, and evaluation analyses allowed the client to see what inputs were contributing the most to higher user engagement. This allowed the client to make better business and data infrastructure decisions, such as whether or not to invest in tracking new data types.
With our new more sophisticated model that could take in vastly more information, we began testing small batches of users the old process had eliminated to see if some of these eliminated users could be profitable. As it turned out, the new model was able to identify tens of millions of users that were just as profitable as the current pool of active users. This means suddenly our client had a new business opportunity that could be executed upon their existing platforms. With this successful experiment, we decided to build the model to scale and deploy a production system.
The Results:
From idea to production, the project took 6 months. These new users recommended by the Komodo model brought in $115,000 of new revenue its first month at production scale, and continues to bring in new revenue every month, even after the contract’s conclusion. And best of all, the client received a ‘set it and forget it’ return on their investment. But should they want to build upon its foundations, a handoff phase ensured that the client’s team could make modifications and extend its outputs for different projects in the future. Komodo’s predictive team’s legacy created a profitable new revenue stream and inspired innovation and excitement for the future of data-driven business channels.